As we’ve all experienced over the last year, it is much harder to have a conversation with a facemask on. Not only does the opaque mask prevent lip reading, it also muffles the sound at higher frequencies. This is particularly problematic for people who have a hearing impairment. I’m working on a UKRI project headed up by Michael Stone at Manchester University to try and improve the design of facemasks for better communication.
What has your experience with communicating with a facemask? Please comment below.
Manikin tests
Our first set of acoustic experiments have used a manikin with a loudspeaker in its mouth (see Figure 1). We measured how much the sound pressure level is attenuated when a mask is added. This is done at a microphone 1m in front of the manikin’s mouth. This misses some effects that are present with real humans, such as movements of the face and air flow while talking. The advantage of using a manikin is it enables a more controlled and repeatable experiment.

Surgical mask 
Clear acetate insert in cloth mask 
Cloth mask
Figure 2 shows a typical result for the three masks shown in Figure 1. The insertion loss is how much sound is attenuated by the mask, so for example, the cloth mask attenuates high frequency sound much more than the surgical mask. The most important range for speech is between 125 and 8000 Hz.
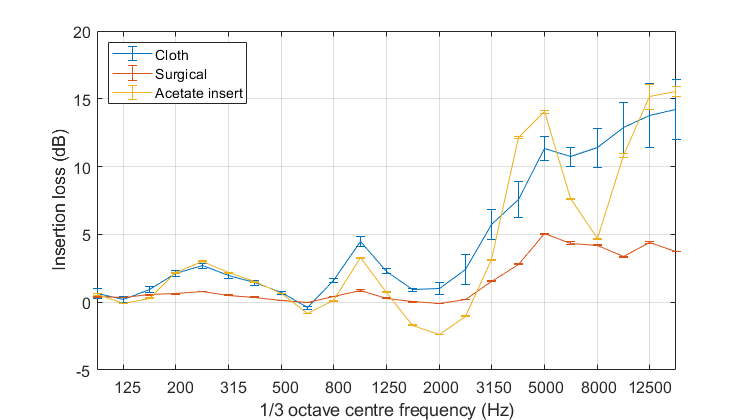
The greater attenuation of the cloth mask relative to the surgical one is to be expected. The cloth mask has more layers and is thicker than the surgical one, leading to more viscous losses as the air vibrates through the porous material.
Here is a sound example to hear the difference. This is a female talking against a background babble of four other talkers. In each sound file, first you’ll hear the case with the mask on, then with the mask off. For the cloth mask, the loss of the high frequencies with the mask on (first part of the sound file) is evident, for example the ‘t’ at the end of the first word “just” is harder to pick out.
The common surgical mask is much more transparent to sound, I had to listen to it a few times to pick out the differences.
Adding a clear section to the mask allows lip reading, but doesn’t remove the muffling of the sound as Figure 2 shows. Indeed when an acetate insert was added in the cloth mask dips and peaks in the insertion loss were created. This is due to the way the acetate vibrates in its modes. While the acetate+cloth mask amplifies around 2000 Hz (insertion loss goes negative), it performs worse than the purely cloth mask around 5000 Hz. If you listen to the sound sample below, you can hear how the timbre of the voice changes due to this uneven attenuation.
While what words are being said is audible for each of the facemasks, the effort required to listen and pick out what is being said is increased for the masks with greater attenuation.
What’s next?
We’re now doing tests with human speakers to examine the effects of air flow and face movements on the mask attenuation. We also have a prototype mask with a clear insert that performs better than any of those shown in Figure 1&2. More information to follow when we’ve done more tests on it. Salford’s Maker Space is also working on other improvements to the prototype.
Measurement details
- Measurements were made using a sine sweep to get a transfer function from source (loudspeaker in the manikin) to the receiver (microphone 1m in front of manikin).
- Auralisations were created by convolving the measured impulse responses with dry anechoic speech. An EQ was applied to remove the frequency response of the head and torso mouth simulator.